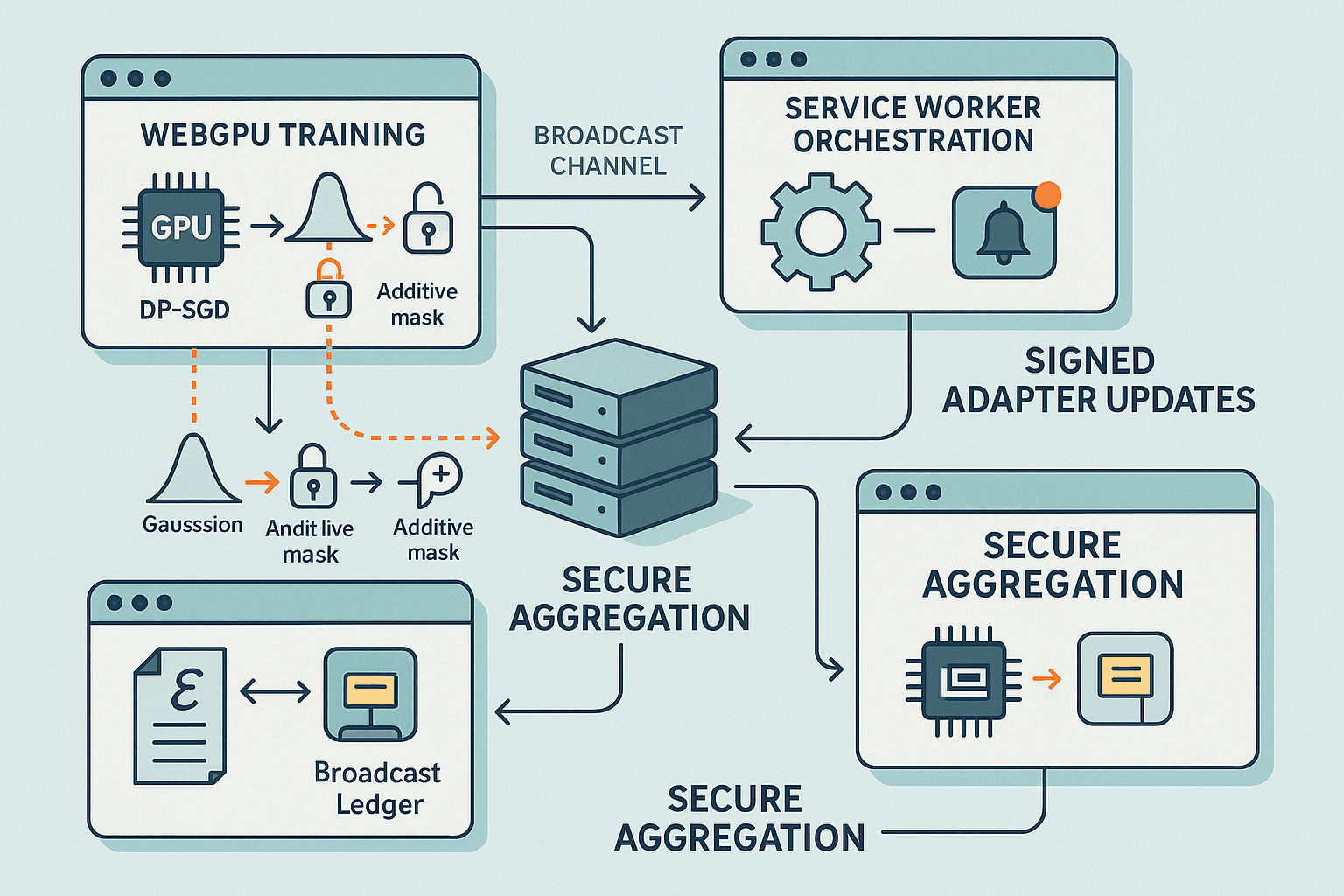
Executive summary
Running federated learning (FL) directly in the browser is no longer a thought experiment. With WebGPU, WASM SIMD/threads, and modern service worker primitives, we can perform serious on-device adaptation for AI browser agents while maintaining tight privacy guarantees. This article lays out a concrete, production-viable pipeline:
- Train only lightweight task adapters (e.g., LoRA) inside tabs via WebGPU.
- Enforce user-level differential privacy with DP-SGD and per-user privacy budgets.
- Coordinate FL rounds using Service Workers, Background Sync/Web Push, and BroadcastChannel.
- Use secure aggregation and robust server-side aggregation to handle dropouts and adversarial clients.
- Ship signed adapter updates via the Cache API/OPFS without exfiltrating PII.
We’ll go deep on design choices, implementation details, JS/WGSL snippets, and how to make it work under real browser constraints.
- Why train in the browser at all?
- Privacy by default: Raw user content never leaves the device. Only DP-noised, optionally masked updates are shared.
- Personalization where it matters: Browser agents see the DOM, user browsing patterns, and tool-use contexts that cloud models don’t. Adapting to local behavior boosts success rates for navigation, extraction, and automation tasks.
- Cost and scale: Leveraging end-user compute amortizes server costs and can reduce latency for post-training inference.
- Regulatory alignment: Differential privacy with strict per-user budgets supports compliance postures for sensitive markets.
Threat model and goals
- We assume an honest-but-curious server and potentially malicious clients. We seek client-level privacy (updates alone should reveal little about any single user) and resilience to model poisoning/backdoors.
- No raw PII or text is ever sent to the server. Gradients are clipped and DP-noised locally, then passed through secure aggregation. Adapters only (no base weights) are updated.
- Architecture overview
- On-device model: Quantized base LLM (e.g., 4-bit) with LoRA adapters trained in FP16/FP32 for stability.
- Training triggers: Short episodes when the agent completes tasks and the user gives implicit/explicit feedback; or scheduled, opt-in background rounds.
- Compute stack: WebGPU for forward/backward and per-example gradient clipping; WASM+SIMD for accounting and serialization; WebCrypto for PRNG/secrets.
- Orchestration: A Service Worker coordinates rounds, maintains a local privacy ledger, synchronizes with all tabs via BroadcastChannel, and handles network/queueing.
- Transport: HTTP/3 or WebTransport with secure aggregation handshakes (Bonawitz-style pairwise masks) and masked update upload.
- Server: Round selection, adaptive sampling, robust aggregation (FedAdam + coordinate-wise median/trim), DP auditing, update signing, and phased rollout.
Storage
- Origin Private File System (OPFS) or IndexedDB for model shards, adapter snapshots, and privacy ledger.
- Cache API for signed model artifacts with ETags and rollbacks.
- Model design: adapters and quantization that fit the browser
- Base model: A compact LLM in the 1–7B range works on desktop GPUs with WebGPU; mobile will lean smaller. Quantize to 4-bit for inference; keep low-rank adapters (LoRA, IA3, or task adapters) in FP16 for training.
- Parameter budget: LoRA with r=8–16 across attention QKV and MLP projection matrices typically adds 0.2–1.0% parameters relative to base—tens of MBs instead of GBs.
- Fine-tuning target: Supervised preference-aligned snippets (e.g., next-action prediction, tool call selection) derived from local task outcomes. We avoid end-to-end instruction SFT in the browser due to memory and step count constraints.
- Optimizer: DP-SGD or DP-AdamW with microbatching. Start with DP-SGD to keep the privacy accountant simple and stable.
- Mixed precision: Use WebGPU f16 where available; accumulate in f32.
- Differential privacy mechanics that actually hold up
We enforce user-level DP at the client:
- Per-example gradient computation (or per-microbatch) with clipping norm C.
- Add Gaussian noise N(0, σ^2 C^2 I) to the clipped gradient.
- Privacy accountant tracks (ε, δ) using Rényi DP (RDP) composition across steps.
Key parameters:
- Sampling rate q = b / N_active, where b is local batch size, N_active is the number of participating clients this round. In cross-device FL, server-side subsampling approximates Poisson sampling.
- Noise multiplier σ: choose to target ε in [2, 8] per user per 30-day window for practical utility with strong privacy.
- δ set to 1/N_total_users^1.1 (e.g., 1e-7–1e-9).
A minimal RDP accountant (Mironov 2017) for Gaussian mechanism can be implemented locally to meter budget and refuse additional rounds if a user’s cap is reached.
- WebGPU training pipeline: skeleton implementation
Prereqs
- Feature detection: navigator.gpu, adapter.features for shader-f16.
- Cross-origin isolation isn’t required for WebGPU, but using SharedArrayBuffer for fast data pipelines does need COOP/COEP.
- For randomness, use WebCrypto’s getRandomValues for seeds; implement a counter-based PRNG (e.g., Philox, Threefry) in WGSL or generate noise on CPU and upload.
High-level flow
- Load base model and current adapter weights from Cache API/OPFS.
- Prepare a micro-dataset of local training examples (tokenized) held in memory only for the session.
- For t = 1..T_local:
- Forward pass, compute per-example loss.
- Backward pass to per-example gradients over adapter parameters.
- Clip each example’s gradient to norm C; average.
- Add Gaussian noise; update adapter weights with DP-SGD.
- Serialize masked DP update and send to server via SW.
WGSL kernel sketch: per-example L2 norm and clipping
wgslstruct Grad { data: array<f32>; }; @group(0) @binding(0) var<storage, read> grads: array<Grad>; // [B] examples @group(0) @binding(1) var<storage, read_write> clipped: array<f32>; // flat param array @group(0) @binding(2) var<storage, read> scaleBuf: array<f32>; // per-example scale @compute @workgroup_size(256) fn l2_norm_and_clip(@builtin(global_invocation_id) gid: vec3<u32>) { let idx = gid.x; // over parameters // This kernel assumes B small; scaleBuf[e] holds min(1, C/||g_e||) // Accumulate scaled gradients across examples var acc: f32 = 0.0; for (var e: u32 = 0u; e < B; e = e + 1u) { let g = grads[e].data[idx]; acc = acc + g * scaleBuf[e]; } // Write averaged clipped gradient clipped[idx] = acc / f32(B); }
Computing per-example scales requires an earlier pass to compute ||g_e|| and then scale = min(1, C / ||g_e||). Example pseudocode in TS for the two-pass approach with WebGPU:
tsasync function clipAndNoise(device: GPUDevice, gradsBufs: GPUBuffer[], C: number, sigma: number) { // gradsBufs: array of GPUBuffer, one per example, same length (numParams) // 1) Compute per-example L2 norms const norms = await computeL2Norms(device, gradsBufs); // returns Float32Array length B const scales = norms.map(n => Math.min(1.0, C / (n + 1e-12))); // 2) Upload scales and launch clipping + averaging kernel const scaleBuf = device.createBuffer({ size: scales.byteLength, usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(scaleBuf, 0, new Float32Array(scales)); const clippedBuf = device.createBuffer({ size: NUM_PARAMS * 4, usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC | GPUBufferUsage.COPY_DST, }); // bind groups, pipeline omitted for brevity // dispatch workgroups over NUM_PARAMS // 3) Add Gaussian noise on CPU and add to clipped gradient (or in WGSL) const noise = sampleGaussian(NUM_PARAMS, sigma * C); // WebCrypto-seeded const clipped = await readBack(device, clippedBuf); for (let i = 0; i < NUM_PARAMS; i++) clipped[i] += noise[i]; return clipped; // DP-noised, averaged gradient }
Gaussian noise sampling
- CPU: Box-Muller or Ziggurat with WebCrypto-seeded PRNG; then upload as a GPUBuffer and fuse addition on-GPU.
- GPU: Implement a counter-based PRNG (Philox4x32-10) and a normal transform (e.g., Box-Muller or Moro). CPU RNG is typically simpler and sufficient at our scales.
Optimizer step (DP-SGD)
tsfunction dpSgdStep(params: Float32Array, grads: Float32Array, lr: number, weightDecay = 0.0) { for (let i = 0; i < params.length; i++) { const g = grads[i] + weightDecay * params[i]; params[i] -= lr * g; } }
Note: In practice, you’ll maintain adapter parameters in a GPUBuffer; for clarity, this snippet uses CPU arrays. ONNX Runtime Web or custom WebGPU pipelines can keep steps on-GPU.
- Privacy ledger and budgeting
Enforce per-user budgets client-side and verify server-side sanity without identifying users.
- Ledger: Persist an append-only log of training events in IndexedDB/OPFS with a server-signed monotonic time token (to resist local clock rollback). Each event stores (roundId, steps, q, sigma, delta, epsIncrementRDP->(ε, δ)).
- Budget cap: e.g., ε_max = 6.0 per 30 days with δ = 1e-8. Halt local participation when reached; the Service Worker refuses new rounds until the window slides.
- Server metering: The server issues anonymous, rate-limited participation tokens (e.g., Privacy Pass style) so a single device cannot exceed a global participation quota without linking identity.
Minimal RDP accountant (sketch)
ts// Using RDP of Gaussian mechanism and converting to (ε, δ) // See Mironov (2017) and TensorFlow Privacy for reference function composeRdpGaussian(orders: number[], q: number, sigma: number, steps: number): number[] { // Returns alpha->RDP(alpha) return orders.map(alpha => { // Subsampled Gaussian RDP (approx). For simplicity, use upper bound: // RDP(alpha) <= (alpha * q^2) / (2 * sigma^2 - 2) for sigma^2 > 1 const term = (alpha * q * q) / Math.max(2 * sigma * sigma - 2, 1e-12); return steps * term; }); } function rdpToEps(orders: number[], rdp: number[], delta: number): number { let eps = Infinity; for (let i = 0; i < orders.length; i++) { const a = orders[i]; eps = Math.min(eps, rdp[i] + Math.log(1 / delta) / (a - 1)); } return eps; }
Use a richer accountant (e.g., Moments Accountant or exact subsampled Gaussian RDP) for production; libraries from Opacus or TF-Privacy can be ported.
- Orchestrating FL rounds with Service Workers
Service Worker responsibilities
- Join/leave rounds, enforce rate limits and privacy budget gates.
- Collect DP-noised updates from any active tabs via BroadcastChannel.
- Handle offline queueing and retry with Background Sync (where supported) and keepalive fetch.
- Store/serve model artifacts via Cache API.
Message flows
- BroadcastChannel “fl-control”: SW announces a new round and hyperparams (C, σ, lr, epochs, target adapter layers, token budget).
- Content scripts/pages respond with capability info (VRAM, WebGPU adapter limits) and willingness to participate.
- SW selects a single tab/context to perform training to avoid contention; others idle.
Service Worker sketch
ts// sw.js const bc = new BroadcastChannel('fl-control'); let roundConfig = null; self.addEventListener('push', event => { // Server notifies new round availability event.waitUntil(handlePush(JSON.parse(event.data.text()))); }); async function handlePush(msg) { if (msg.type === 'ROUND_INVITE') { // Check privacy budget and device constraints const ok = await hasBudget(msg.roundId) && await deviceHealthy(); if (!ok) return; roundConfig = msg.config; bc.postMessage({ type: 'ROUND_START', config: roundConfig }); } } bc.onmessage = async (e) => { const m = e.data; if (m.type === 'ROUND_RESULT') { // m.update: Uint8Array (masked DP update) await uploadMaskedUpdate(m.update, m.proof); } }; async function uploadMaskedUpdate(update, proof) { await fetch('/fl/submit', { method: 'POST', headers: { 'Content-Type': 'application/octet-stream' }, body: update, // Already masked and DP-noised keepalive: true, }); }
Tab-side participation
ts// page.js const bc = new BroadcastChannel('fl-control'); bc.onmessage = async (e) => { const m = e.data; if (m.type === 'ROUND_START') { const { config } = m; const res = await trainLocalAdapter(config); // res.update is masked DP update bc.postMessage({ type: 'ROUND_RESULT', update: res.update, proof: res.proof }); } };
Scheduling
- Web Push (preferred): Server pings when it has capacity; user opt-in required.
- Periodic Background Sync: Chrome-origin trial; limited support. Fallback to app-initiated checks when tab is open.
- navigator.locks: Ensure only one trainer runs per origin at a time.
- Secure aggregation: mask before upload
Use an additive masking protocol so the server cannot see individual updates, only their sum. The classic approach (Bonawitz et al., 2017) works with dropout tolerance extensions.
High-level steps per round
- Pairwise keys: Each client i establishes ephemeral shared secrets s_ij with peers via the server as a relay (or via WebRTC data channels). Use X25519 (WebCrypto) for ECDH.
- Masks: For sorted peer list, client i builds mask M_i = Σ_j PRG(s_ij) * sign(i, j) over the parameter dimension, where signs cancel across pairs.
- Upload: Client sends U_i + M_i (plus DP noise already added) to server.
- Unmasking: If all clients participate, masks cancel in the sum Σ_i(U_i + M_i) = Σ_i U_i. For dropouts, use secret sharing to allow mask recovery or pairwise mask reveal of dropped peers.
Browser implementation notes
- WebCrypto subtle.generateKey({ name: 'ECDH', namedCurve: 'X25519' }) is available in modern browsers.
- Use HKDF to derive per-round PRG keys. PRG can be ChaCha20 or AES-CTR (WebCrypto) producing float32 noise via reinterpretation/scaling.
- Dropout tolerance: Employ SecAgg+ or Prio3-style share splitting so that if a peer drops, masks can be reconstructed from a threshold of survivors without revealing any single client’s update.
Pseudocode: building the mask
tsasync function makeMask(peerPublicKeys: CryptoKey[], myKeyPair: CryptoKeyPair, length: number) { const mask = new Float32Array(length); // Deterministic peer ordering const peers = peerPublicKeys.slice().sort(byKeyId); for (const pk of peers) { const shared = await subtle.deriveBits({ name: 'ECDH', public: pk }, myKeyPair.privateKey, 256); const key = await subtle.importKey('raw', await hkdf(shared, 'secagg-round'), { name: 'AES-CTR' }, false, ['encrypt']); const stream = await prg(key, length * 4); // bytes const view = new DataView(stream); const sign = signForPeer(pk); // +1 or -1 based on ordering for (let i = 0; i < length; i++) mask[i] += sign * (view.getInt32(i*4, true) / 0x7fffffff); } return mask; }
Order of operations: clip -> average -> add Gaussian DP noise -> add SecAgg mask -> upload. Noise must be added client-side regardless of secure aggregation to achieve central DP guarantees.
- Robust aggregation and adversarial defenses on the server
Server tasks:
- Participation sampling: Randomly select a subset for each round to control q and system load.
- Deadline and straggler handling: Close the round when min(K, quorum) updates received or timeout expires.
- Anomaly detection: Reject updates with large norm, extreme cosine distance from median, or failing validation.
- Robust aggregators:
- Coordinate-wise median or trimmed mean to reduce outlier influence.
- Krum/Multi-Krum (Blanchard et al.) or FoolsGold against Sybils/backdoors.
- FLTrust-style server reference scoring when a small, non-sensitive, public calibration dataset is available.
- Optimizer: FedAdam or FedYogi over adapter parameters to accelerate convergence.
Server-side sketch (Python)
python# aggregator.py import numpy as np def robust_mean(updates, trim=0.1): # updates: list of np.array vectors X = np.stack(updates, axis=0) k = int(trim * X.shape[0]) lower = np.partition(X, k, axis=0)[k] upper = np.partition(X, X.shape[0]-k-1, axis=0)[X.shape[0]-k-1] mask = (X >= lower) & (X <= upper) # avoid all-false columns weights = mask.astype(np.float32) weights[weights.sum(axis=0)==0, :] = 1.0 return (X * weights).sum(axis=0) / weights.sum(axis=0) class FedAdam: def __init__(self, dims, lr=1e-2, beta1=0.9, beta2=0.99, eps=1e-8): self.m = np.zeros(dims) self.v = np.zeros(dims) self.t = 0 self.lr = lr self.b1 = beta1 self.b2 = beta2 self.eps = eps def step(self, w, grad): self.t += 1 self.m = self.b1 * self.m + (1 - self.b1) * grad self.v = self.b2 * self.v + (1 - self.b2) * (grad ** 2) mhat = self.m / (1 - self.b1 ** self.t) vhat = self.v / (1 - self.b2 ** self.t) return w - self.lr * mhat / (np.sqrt(vhat) + self.eps)
You can combine robust_mean with an update norm cap and cosine-similarity filtering before the optimizer step. Always verify that the post-aggregation update improves a held-out, non-sensitive public task to guard against stealthy backdoors.
- Handling client dropouts and resource volatility
- Short rounds: Target 1–2 minutes wall time to reduce churn exposure.
- Quorum: Proceed once a minimum number of updates arrives; late arrivals are rolled into the next round.
- Adaptive microbatching: Clients self-report VRAM and throttling state; server prescribes per-client token budgets to fit resource envelopes.
- Checkpoints: Keep last-known-good adapter snapshot in Cache API; resume if a tab reloads.
- SecAgg dropout tolerance: Use share splitting to allow mask recovery when peers drop unexpectedly.
- Update shipping without PII
Artifact pipeline
- Build: Server aggregates and produces a new adapter checkpoint (e.g., LoRA tensors) and a manifest.json with version, SHA-256, and hyperparams.
- Sign: Sign manifest with Ed25519; publish to a CDN with immutable URLs.
- Cache: Service Worker fetches, validates signature, and caches with ETag. Roll back if the new adapter fails local health checks.
Verification snippet
tsasync function verifyManifest(manifest, sig, pubKey) { const enc = new TextEncoder(); const data = enc.encode(JSON.stringify(manifest)); const key = await crypto.subtle.importKey( 'raw', pubKey, { name: 'NODE-ED25519', namedCurve: 'NODE-ED25519' }, false, ['verify'] ); const ok = await crypto.subtle.verify('NODE-ED25519', key, sig, data); if (!ok) throw new Error('Manifest signature invalid'); }
On activation
- Merge/Load adapters on model init.
- Gradually roll out (e.g., 5% → 25% → 100%) guarded by a feature flag in local storage. Server controls cohorts via Web Push topic.
- Data governance: never persist raw sensitive data
- Ephemeral buffers: Training examples live only in memory; zeroed after each step. Use structuredClone with transfer to avoid stray copies.
- Logging: No console.debug of tensors in production builds.
- Telemetry: Aggregated, DP-sanitized counters only (e.g., round success/failure, latency histograms), or rely entirely on FL metrics.
- Red-teaming: Attempt gradient inversion attacks locally to validate DP parameters before rollout.
-
Putting it together: end-to-end example flow
-
Enrollment: User opts into privacy-preserving improvement. SW initializes privacy ledger with ε_max=6, δ=1e-8.
-
Round invite: Server sends a push with round config: target layers, lr=5e-5, C=0.5, σ=1.0, epochs=1, token budget=256.
-
Tab selection: SW chooses an active tab, posts ROUND_START. Tab gathers recent agent episodes (e.g., tool decision, DOM extraction correctness) as in-memory examples.
-
Training: WebGPU runs T steps of DP-SGD over adapters, adding Gaussian noise; SW checks budget mid-round if needed.
-
SecAgg: Tab performs ECDH with N peers, builds additive mask, applies it to the DP update.
-
Upload: SW uploads masked update; server collects K updates, performs secure unmasking to get aggregate, runs robust aggregation + FedAdam.
-
Validation: Server evaluates on public tasks; if metrics >= guardrails, signs and publishes new adapter.
-
Rollout: SW fetches, verifies, caches, and swaps the adapter on next page load.
-
Performance and practicality
- Throughput: On mid-range laptops, training r=8 LoRA adapters over a 3–7B model with microbatch=1–2 at sequence length 128–256 can hit 1–4 steps/s; enough for small local improvements.
- Memory: Keep base model in 4-bit and only train adapters in FP16; checkpointing and zipped shards reduce footprint.
- Energy: Ensure training is gated by user-idle heuristics (Page Visibility API,
navigator.scheduling.isInputPending()) and connection type; throttle on battery. - Cross-browser: WebGPU is stable in Chromium and Firefox (behind pref on some platforms); provide wasm/webgl fallback for non-participation, or simply skip training.
- Security and abuse prevention
- Integrity: Require signed round configs; authenticate server with cert pinning where applicable.
- Sybil defense: Anonymous but rate-limited tokens; robust aggregation that discounts highly similar updates from cohorts.
- Backdoor scans: Synthetic canary prompts; if a backdoor triggers, auto-rollback to previous adapter and quarantine cohort.
- Reproducibility: Deterministic PRNG seeds per round (plus DP noise) logged locally for audit without exposing secrets.
- Testing and evaluation
- Synthetic A/B: Build synthetic browser tasks (form-fill, navigation, extraction) with public pages to validate convergence.
- Privacy audits: Use TF-Privacy/Opacus offline to simulate the same DP parameters and verify (ε, δ).
- Fault injection: Randomly kill training tabs, drop network mid-upload, simulate adversarial updates (scaled or sign-flipped) and confirm aggregator resilience.
- Metrics: Success@k for tool choice, time-to-complete tasks, hallucination/error rates in extraction.
- Implementation choices: libraries and references
-
Runtime and kernels
- WebGPU: Native device, pipelines, and WGSL custom ops.
- ONNX Runtime Web (WebGPU backend) can help with forward/backward for some models; for LLMs, consider MLC/TVM Unity stacks which target WebGPU.
- Tokenization: WASM (fast BPE/unigram) via wasm-pack or tiktoken-wasm.
-
Crypto and privacy
- WebCrypto SubtleCrypto for ECDH, HKDF, AES-CTR/ChaCha20 streams.
- DP: Port a small RDP accountant; tune σ to stay within budget.
- Secure aggregation: Follow Bonawitz et al. 2017; see also SecAgg+ and Prio3 for dropout tolerance.
-
Server
- Aggregation: Numpy/JAX/PyTorch.
- Storage: Versioned adapter manifests and shards on a CDN; TUF-style update metadata for rollback.
References (highly recommended)
- McMahan et al. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data (FedAvg).
- Abadi et al. 2016. Deep Learning with Differential Privacy (DP-SGD).
- Mironov 2017. Rényi Differential Privacy.
- Bonawitz et al. 2017. Practical Secure Aggregation for Privacy-Preserving ML.
- Reddi et al. 2021. Adaptive Federated Optimization (FedAdam, FedYogi).
- Blanchard et al. 2017. Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent (Krum).
- Pillutla et al. 2022. Robust Aggregation for FL via Median-of-Means.
- Kairouz et al. 2021. Advances and Open Problems in Federated Learning (survey).
- Common pitfalls and a pragmatic checklist
- Don’t compute DP noise after secure aggregation server-side; add it on-device before masking to bound per-user leakage.
- Don’t persist raw training examples; zero memory and avoid serialization.
- Ensure model update manifests are signed and validated; corrupted adapters can brick your client or leak data via prompt injection side-channels.
- Keep rounds short; prevent tab contention with navigator.locks.
- Monitor real epsilon accrual; halt on budget exhaustion.
- Tune clipping norm C carefully; too small kills signal, too large weakens DP benefits.
- Use robust aggregation; FedAvg alone is brittle against adversaries.
Conclusion
Federated learning in the browser is no longer just a privacy story—it’s an engineering reality. By restricting optimization to small, effective adapter layers; leveraging WebGPU for efficient per-example gradient clipping; enforcing client-side DP-SGD with rigorous budgeting; coordinating work through Service Workers; and hardening the server with secure aggregation and robust optimizers, we can continuously improve browser agents without exfiltrating PII. The architecture here is intentionally opinionated: it avoids fragile full-model fine-tuning, embraces proven cryptographic patterns, and respects the operational constraints of the web platform. If you implement it carefully, you can ship measurable quality gains and maintain a sound privacy posture that stands up to scrutiny.